Progress Update Winter 2018
This is an update on our progress towards our mission in the second half of 2018.
Our mission is to figure out how to use machine learning to support tasks that require thinking and reflection. We focus on approaches that are “scalable” in the sense that better ML or more compute makes them increasingly helpful for supporting and automating deliberation, without requiring additional data generated by humans.
Over the last six months, our research focused on factored cognition as a potential route towards scalable automation of human-endorsed reasoning. This approach is based on decomposing the cognitive work involved in answering difficult questions into small, mostly context-free pieces that can be supervised by individuals who don't know the big picture.
Our work was split between better understanding the foundations of computing paradigms for factored cognition, building apps that facilitate experiments with human participants, and running such experiments.
Towards these goals, we:
Extended Mosaic, our app for recursive question-answering, with scheduling functionality. This allowed us to run multi-user experiments.
Created a new lightweight app, Relay, for running factored cognition experiments where participants work on a single shared workspace in serial.
Ran about 100 participant-hours of experiments, split evenly between Mosaic and Relay.
Created Affable, a Haskell-based recursive question-answer system that supports cache-based automation and is our new basis for experimenting with more advanced features.
Hired a research engineer, Derek Elkins.
Received grants from FLI and the Long-Term Future EA Fund.
We provide context and details for these achievements below.
Foundations
To better understand the foundations of factored cognition, we've started a new Haskell-based command-line prototype for recursive question-answering, and we've continued doing conceptual work.
Affable: A Haskell-based lab for recursive QA systems
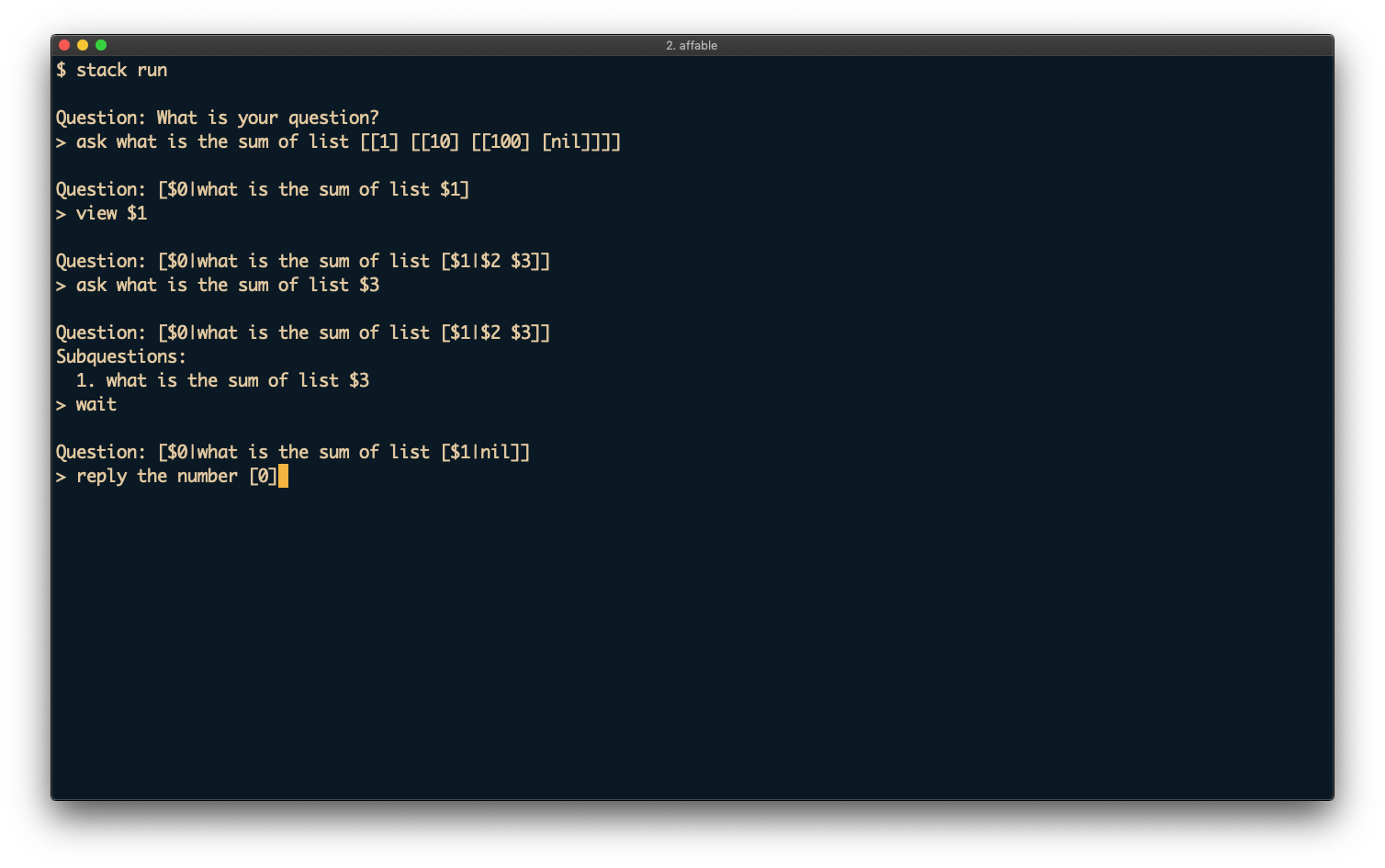
Affable is a new open-source prototype for recursive question-answering, implemented by Derek Elkins in Haskell. It is the successor to Patchwork, our previous Python-based prototype.
Affable was designed to serve as a platform for multiple prototypes to explore the design space of recursive question-answering systems. The current version of Affable presents a command-line interface similar to Patchwork's. Affable is effectively an interpreter for a simple functional language, executing code provided on an as-needed basis via human interaction. As a result, automation resulting from cached human actions can be exported as reasonably readable Haskell code.
Affable maintains all of its state in an SQL database. Making the data model explicit and externally accessible has several advantages:
- It supports upcoming features like reflection and distillation.
- It helps diagnostics, instrumentation, and scalability.
- It simplifies the transition to a web app later on.
To verify that arbitrary computation can be automated using a finite number of human interactions, Derek implemented an abstract machine for the call-by-value lambda calculus, the CEK machine, through question-answering. Asking the question "What does [expression] evaluate to?" for two small example lambda terms, namely (λx.x)(λy.y) and (λx.λy.x)(λw.w)(λz.z), was enough to completely automate the evaluation of all future lambda terms, including Church numeral exponentiation and infinite loops. Derek verified the correctness of the learned behavior by looking at the automation state formatted as code.
Conceptual work: Scheduling, pointers, automation
As part of the implementation of Affable, Derek wrote internal documents on the semantics of pointers and on potential extensions for cache-based automation.
Following up on our taxonomy, I've been writing about approaches to scheduling cognitive work. Any app for factored cognition needs to decide which workspace should be worked on next, by human participants or by automation. The most natural approach, in the long run, is to delegate the decision about how to allocate cognitive work to the question-answering system (e.g. by asking "Which workspace should we show next to user #312?"). This seems worthwhile to think about on its own terms, but also as a representative instance of meta-reasoning within the QA system. I expect this sort of meta-reasoning to be critical to the promise and challenge of factored cognition.
We haven't cleaned up any of these notes yet, and doing so is not high priority for us, but we would be happy to share them with interested parties.
Apps for experiments
To run factored cognition experiments with human participants, we've continued building our web app for recursive question-answering, Mosaic. We've also started a new exploratory short-term project, Relay, which has its own lightweight web app that lets us explore what decomposition strategies people come up with when we don't enforce recursive question-answer structure.
The Mosaic and Relay apps don't support automation or sophisticated programming language features, but they let us gather empirical evidence now while we work out more full-featured systems as part of our foundations research program. We expect that foundations and empirical research will merge over time, and that later experiments will increasingly supplement human work with automation.
Mosaic: A feature-rich app for tree-structured experiments
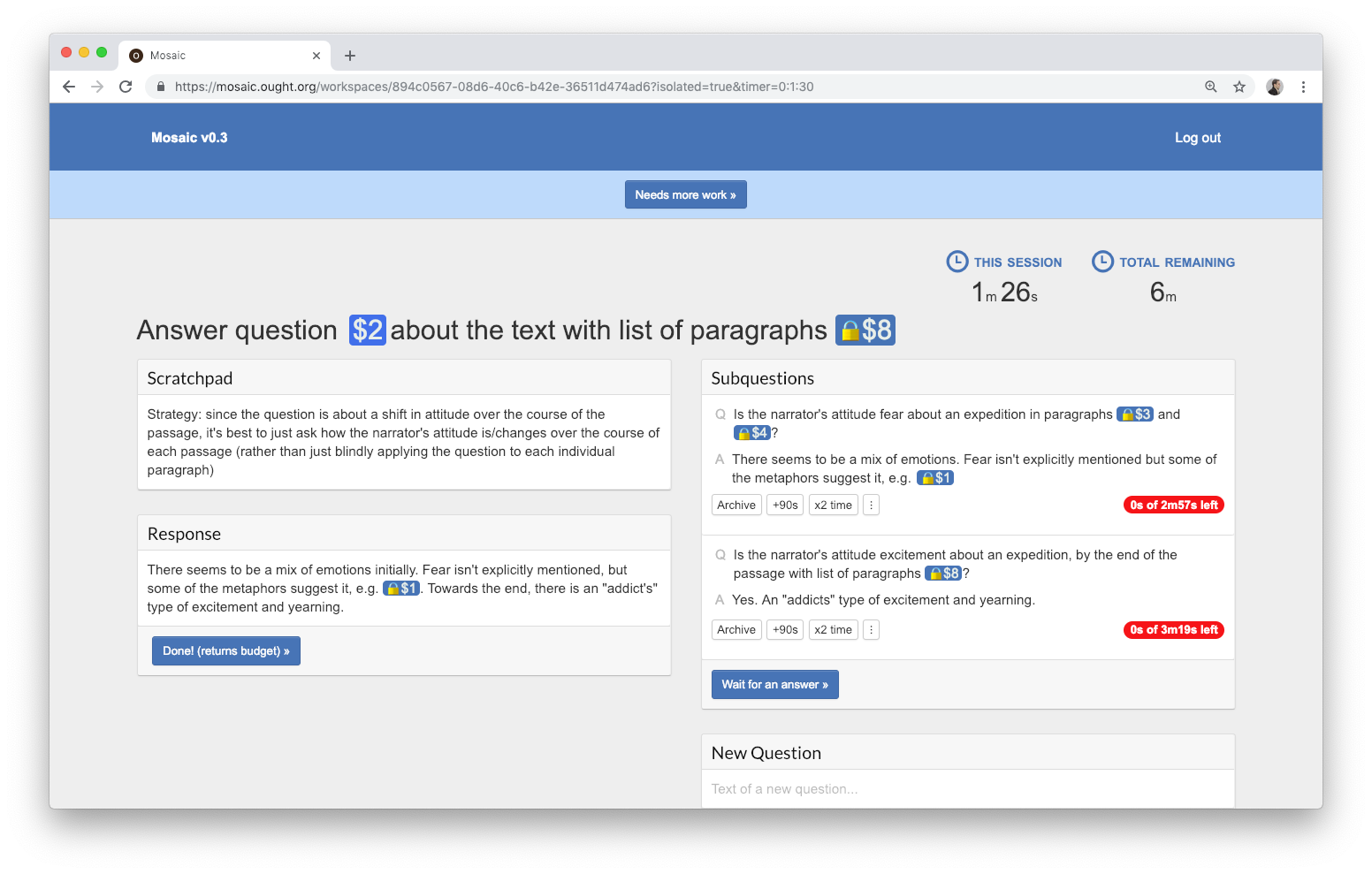
Over the past six months, Zak Miller has overhauled the style of Mosaic, made numerous usability improvements (such as automatically exporting any text enclosed in square brackets), and he has introduced the following features:
Automated scheduling: A scheduler ensures that multiple users aren’t working on the same workspace at the same time, that work gets distributed evenly across top-level questions, and that subquestions get resolved before their parents. Previously, we thought we'd be able to run experiments with human managers instead of automated scheduling. This turned out to be more difficult for the human scheduler than we expected, but once we implemented automated scheduling, we were in a good position to run multi-user experiments.
Time budgets: Workspaces are now assigned an amount of time that serves as a budget. This budget is spent when a user works on the workspace, and can be passed along when a user creates a subquestion.
Bandwidth constraints: Time budgets are not the only way to push users to break up cognitive work into small units. Zak has also implemented bandwidth constraints, where each workspace limits the incoming and outgoing number of characters.
Oracles: Sometimes it’s clear that a certain question can be answered using decomposition. In this case, we don’t learn much by having participants go through this process. To address this, we’ve implemented oracles. Oracles are users who have unlimited budgets and full background information. Oracles directly answer the sub-questions that would provide the least evidence about whether decomposition could work, and leave the more interesting questions for non-oracle participants.
Relay: A lightweight app for sequential experiments
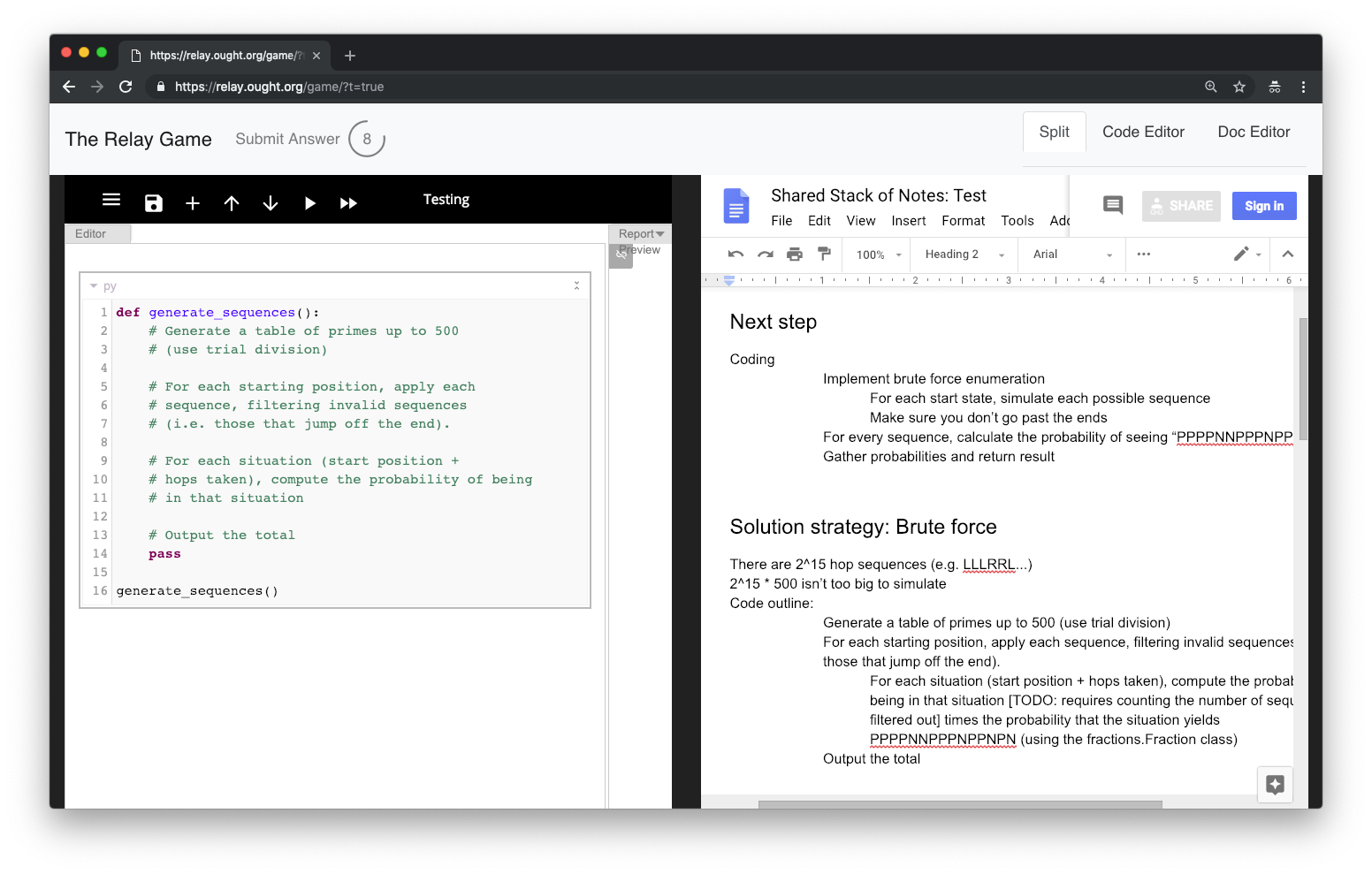
Ben Goldhaber created the Relay web app. While Mosaic is based on a particular hypothesis about how to structure distributed cognition, the aim behind Relay is to create a more minimal, flexible app that allows us to explore alternatives.
In each Relay experiment, participants iteratively make changes to a workspace. There is a strict time limit per person (e.g. 10 minutes), but we don't enforce decomposition otherwise.
The web app is composed of two main views. The first is a dashboard, where participants can click to start working on a new question, view previous questions they’ve participated in, and chat with other participants.
The second is the workspace page, which enforces the time limit and hosts tools that a participant can use to answer the question and pass information to future participants. The tools are customizable per question so that we can experiment with different types of supporting infrastructure (e.g. Google Docs, Workflowy, spreadsheets, IDEs).
Experiments
We've been running multi-user experiments for recursive question decomposition (Mosaic) and sequential workspace edits (Relay). In both cases, our long-term goal is to understand to what extent hard cognitive tasks can be solved piecemeal, and what infrastructure and strategies enable this.
Our initial goal is to learn how to run these sorts of experiments in a way that provides evidence on the feasibility of decomposition, and to get to a stage where "simple" problems can reliably be solved in a factored way. In other words, our experiments so far are "exploratory experiments", i.e. experiments that are not aimed at providing substantial evidence for or against the promise of factored cognition, but that help us refine our methods (apps, strategies, choice of questions), and generally help us build intuition for the domain we're studying. This will probably remain the case for at least another few months, and possibly significantly longer.
Recursive question decomposition experiments
In the last two months, we ran seven one-hour online experiments using Mosaic, about one per week. Each experiment had 7-10 participants from OpenAI, MIRI, and similar organizations, for a total of about 50 hours of participant-time. This time was spent on a mix of decomposing questions and discussing feedback and strategies.
For all but one of our experiments, participants collaboratively answered SAT reading comprehension questions (example). For all but our most recent experiment, participants made contributions under time constraints, generally 90 seconds per workspace.
Let's look at our second experiment in more detail to give a flavor, and then review summary information for all experiments:
- Participants saw one workspace at a time, such as this workspace.
- For each SAT question, we can visualize the decomposition generated by participants as a tree.
- Participants answered five top-level questions, corresponding to five trees (1, 2, 3, 4, 5).
- During the experiment, participants met in a chat and discussed strategy and issues. This feedback document summarizes the discussion.
- In addition to feedback, we have also been collecting question decomposition strategies. (This document was built up over the course of multiple experiments.)
We have similar data for the other six experiments.
What have we learned?
Iteration in teams: Early on, from internal experiments and discussion, we learned that we want a mostly persistent group of participants that can acquire expertise in how to decompose questions, and that can iterate on strategies.
No holds barred: In early internal experiments, we required users to limit what they do (e.g. don't use all available time, don't expand too many pointers). To simplify participating, we switched to the "no holds barred" where participants can do whatever they want (within the constraints imposed by Mosaic) to solve the overall question.
Infrastructure improvements: We learned a lot about how to build better infrastructure for decomposing questions. Almost all of the improvements discussed above in the section on Mosaic app improvements are the result of suggestions by participants, and the seven feedback documents contain many suggestions that we haven't yet implemented.
Limit bandwidth, not time: We learned that, while time budgets (e.g. 90 seconds per workspace) do enforce factored cognition, the frantic action they induce might make the problem harder than necessary. We are now more optimistic about bandwidth-limited experiments (e.g. each workspace can read/write at most 400 characters of input/output).
Need for oracles: It became more salient that factored cognition requires a lot of time to complete interesting questions because of the increased overhead compared to single-person problem-solving. Reading comprehension questions that take a single person 5-10 minutes take at least 1-2 hours with factored cognition. Since our experiments were limited to an hour, we only solved a few of the problems we attempted, even though it seems that we could solve many or all of them if we gave participants more total time. We are addressing this issue by adding oracles that replace the subtrees that seem least informative by directly providing answers.
Need for norms: It became more salient that establishing norms followed by all participants matters a lot. For example, should you always try to use up all the time budget your subtree has, or should you return it if it seems that you can't make good use of it? The strategies document collects norms proposed by participants. We haven't yet gotten to a point where they are consistently endorsed and followed.
Feasibility of factored cognition: I'm hesitant to draw object-level conclusions from the experiments so far, but if I had to say something, I'd say that factored cognition seems neither surprisingly easy nor surprisingly hard. I feel confident that our participants could learn to reliably solve the SAT reading comprehension questions with a bit more iteration and more total time per question, but it has taken iteration on this specific problem to get there, and it's likely that these experiments haven't gotten at the hard core of factored cognition yet.
Over time, we'll push experiments towards being more representative of the sorts of decompositions that we'd use when the aim is to provide training data for ML. This means that participants will use fine-grained decompositions that look more like algorithms for representing and reasoning with concepts ([1], [2]).
We also want to try questions from a wider range of domains and slowly scale up the number of participants for these experiments.
If you're interested in participating, please fill out this form.
Sequential programming experiments
Over the past months, Ben Goldhaber has run Relay experiments. Participants solve a tricky problem in sequence, with each participant contributing 10 minutes of work and then leaving, passing on their notes to the next participant. The goal is to see what strategies participants come up with if we don't enforce the sort of recursive decomposition used in Mosaic.
While the Relay approach is fully general, Ben has so far only applied it to math/algorithms puzzles from Project Euler. We gave participants access to a Google doc and an in-browser IDE. You can preview the interface.
In total 98 users signed up. There were 281 different attempts on 40 different problems, totaling to about 47 hours of time spent solving problems. 25 problems had at least five attempts. 4 problems were successfully solved.
As with Mosaic, we've mostly been learning how to run informative experiments.
What have we learned?
Iteration in teams: Most of our Relay experiments ran with a larger participant pool than Mosaic, and with fewer repeat participants. This caused a number of challenges:
- Doing well as a group requires that individuals don't try to make as much object-level progress as possible, but rather make small contributions and improve the situation the next participant is in. It tends to take participants several attempts at Relay problems before they get a feel for this.
- There is high variance in skill at Project Euler problems. Not all participants would be able to solve these problems even without factorization. This makes it more difficult to say whether failures are due to decomposition.
- When other participants are strangers, it's difficult to be confident that bugs haven't been introduced earlier, and indeed bugs were introduced at times.
We are now running team-based experiments to address these issues.
Infrastructure improvements: Besides adding functionality for solving problems within small teams, Ben added a way for people to see which problems they participated in and to track progress after the fact, and a chat participants can use to discuss strategies.
Strategies: Here are three strategies that seemed helpful:
- Spend some of your round planning for the next participant's round, organizing and simplifying the information the next players are exposed to. This includes restating the problem in simpler terms.
- Create tests and checks for the correctness of subproblems.
- Use a list of tasks, marking tasks that are good next steps and tasks that need to be made more concrete.
While these seem like reasonable ideas, we don't think we have have learned anything substantial yet about what alternative decomposition strategies are most promising.
You can participate at relay.ought.org.
Hiring and collaborations
Hiring
COO
We have continued our search for a COO. So far, we’ve considered about 60 candidates for the role, and have done onsites with 4 candidates. We’ve sourced candidates from our personal networks, 80,000 Hours, and inbound applications.
We have envisioned the COO as a crucial part of Ought’s leadership, while at the same time having major day-to-day responsibilities to keep the organization running well. For these reasons, we’ve held a very high bar for COO candidates across a wide range of competencies, including high-level research understanding and ability to substantially contribute to recruiting in addition to traditional operations. We are considering whether to hire for a more narrow operations role instead, such as Director of Operations or Operations Associate.
Other roles
In November, we hired Derek Elkins as a research engineer after considering about 70 candidates for the role. Derek is a strong Haskell programmer who has worked on projects in functional and logic programming. He was referred to us by Edward Kmett at MIRI.
We've decided that we would like to hire someone whose main job is to run experiments, since doing experiments well is central to our success as an organization. We haven't created a job description for this role yet.
We've updated the job descriptions for the Senior Full-Stack Web Engineer and Researcher roles.
Going forward, we’re prioritizing active recruiting for the web engineer role, and we’ll be on the lookout for strong applicants for the researcher and experimenter roles.
If you’re interested in any of our roles, apply here!
Trial tasks
We created a private Github repository with trial tasks for operations and software engineering that we're sharing with other EA orgs. If this sounds interesting to you, get in touch.
Contractors
We started working with web developer Zak Miller, who has iterated on our Mosaic app to support our Mosaic experiments. We also began working with Ben Goldhaber, who has led our Relay experiments.
Ben West led our Research Engineer and COO hiring processes until he started working at the Center for Effective Altruism in November.
Collaborations
We're not currently actively working on ML projects at Ought, but we're excited to collaborate with interested academics on projects related to factored cognition. This document outlines the sorts of projects we'd be happy to collaborate on.
University of Toronto student Will Saunders visited our office in September, and is visiting again in January. We've started collaborating on a project related to using ML for amplification. If you're interested in this kind of project, get in touch - we're open to hosting academic visitors more frequently in the future.
Organization and funding
Most of our operations capacity has been aimed at recruiting, but we've also made some progress on general organizational improvements, including getting health insurance and other employee benefits.
We received a $225k FLI grant for factored cognition (over two years), and a $10k EA Long-Term Future Fund grant.
Outreach
Paul Christiano talked about Ought on this 80,000 hours podcast episode.
The Factored Cognition presentation was posted as part of the Iterated Amplification sequence on the Alignment Forum. I added a comment with changes I'd make based on what I learned since May 2018.
We've generally fallen short at communicating clearly what Ought does, and in particular feel that our web page is not a great representation of our plans. Our mission has been and still is to find scalable ways to use ML for supporting and automating deliberation, but we want to be clearer about the degree to which we're a research lab vs. aimed at a product, and about how we relate to AI alignment and to other organizations in the space. We hope to remedy this over the coming months.
Plans
Going forward, our priorities are:
Run more multi-user experiments. Get to a point where we can gather substantial evidence on the feasibility of factored cognition.
Continue our foundations research program, integrating reflection, laziness, distillation, speculative execution, and scheduling via question-answering into a single prototype.
Over time, consolidate Mosaic, Affable, and potentially Relay into a single app.
Fill our open roles: COO, web developer, and experimenter.